"Full Stack" Caching Strategy
“Caching is somebody else’s problem, until it’s not” - me (just now)
OK, so that’s a dumb quote I just made up, until it’s not. Microservices do their work, generate their HTTP, response and sent it to the browser. Often, it isn’t until there is a performance or scale problem before a caching strategy gets addressed.
How might a “full stack” caching strategy work? Take a look at the representative diagram below:
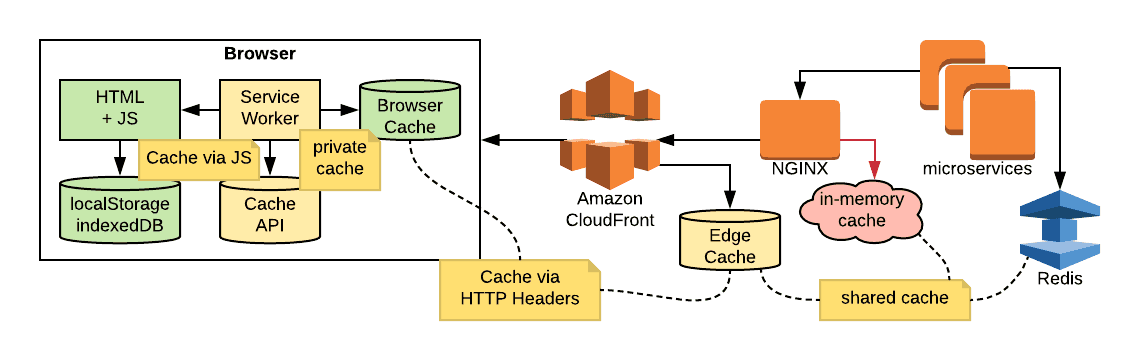
Let’s start with the microservice and follow the response out. How much of a response could benefit from a cache? If it is partially built from of a query result, look at an external cache that works with your database. If it is the entire HTTP response, look at something that works with your web server pipeline. However, with all shared caches, think about security and privacy so you don’t disclose one customer’s data to another. Some additional links:
The response flows through NGINX, which has Content caching functionality. However, this might not be the best place in the architecture for an application with lots of microservices. Some additional links:
The response may flow through a content delivery network (like CloudFront) where it could get cached on the “edge” based on the HTTP cache headers. Early CDNs required you to push out “static content” and use a discrete hostname for browser connection limit reasons. However, mature CDNs allow for “dynamic acceleration” where requests flow through and utilize HTTP cache headers. HTTP/2 connections make a single hostname the preferred option. These distributed shared caches are closer to the browser and give a network latency benefit. Some additional links:
- Caching Content Based on Request Headers - Amazon CloudFront
- Headers - Amazon CloudFront
- Managing How Long Content Stays in an Edge Cache (Expiration) - Amazon CloudFront
Once the response gets to the browser, there is another ecosystem in play. The browser has a private cache (populated by HTTP cache headers) and localStorage/indexedDB (populated by JavaScript code). Additionally, “evergreen” browsers now support Service Workers which can intercept HTTP requests and have access to a Cache API. Some additional links:
- HTTP Caching | Web Fundamentals | Google Developers
- Caching Files with Service Worker | Web | Google Developers
- Using Service Workers - Web APIs | MDN
Any place that has a shared cache needs to be concerned about the cache key. This is more than just the URL, since different users might get different results (e.g. /profile/me) or different Content Types might be returned based on Accept headers. The Vary header is often used as part of the cache key. Some additional links:
This was just a quick overview as there is a lot more complexity to this topic. What key parts are missing? Where in the architecture makes the most sense to you, and how should a development team decide where caching belongs?